Chapter 3 Introduction to Version Control Systems
Preliquisite
Basic knowledge of R, particularly working with RStudio.
Chapter Expectation
By the end of this chapter you should:
- Have installed Git and signed up for a GitHub account
- Know what is and how to version control files using Git
- Fork and make pull requests on GitHub
- Understand what the terms “master”, “head”, and “branch” mean
3.1 Introduction: What and Why Version Control System
When we start doing data analysis and particularly when we start developing functions, we expect to make several incremental changes. Some of these changes will be made by us or other people we are collaborating with. Usually, for each substantial change we make we would save the document under a specific version like version 1, 2, 3 and so on. This process of versioning each change made to a document is a basic local version control system. It is a simple system and easy to use, however, it is hard to know what changes were made and at what point they were introduced. Without this knowledge we are open to challenges like malfunctioning project/code.
Consider a point when a bug is introduced by you or one of your contributors, you would not know what or when a bug was introduced and going through your code could prove to be a tall order. In addition, there are great possibility of losing documents in cases such as a hard disk crash. It is due to these and possibly more challenges that we might not what to rely on this versioning system.
Looking around for a more suitable versioning system, it turns out that programmers have had similar challenges in versioning their scripts. They initially began with a simple versioning system like ours, then moved on to what they call “Local Version Control System” or LVCS, then to “Centralized Version Control System” or CVCS and currently have “Distributed Versioning System” or DVCS.
Their “Local Version Control System” (LVCS) had a simple local database that kept all the changes under revision control. Basically what this system did was store original file and subsequently kept differences in patches such that a file could be re-created to look as it were at any point using the original file and patches as it was at that point. This system was a step up from earlier system, however, it proved difficult when it came to collaboration and therefore a centralized system was developed.
The Centralized Version Control System (CVCS) as the name suggests has a centralized database which enabled different developers to collaborate on projects. Other than collaboration, this system had other advantages such as administration ease as it was easier to manage one centralized database than several localized databases. It was also easy for developers/programmers to know what others were working on. The major draw back for this system is that server downtime meant no updates we made, it is also possible to lose all documents if the central computer crashed and there was no backup. This drawback was a major input in development of “distributed Version Control Systems” (DVCS).
Distributed Version Control Systems (DVCS) enabled developers to download an entire repository unlike CVCS where one retrieved only needed file(s). By doing so, DVCS ensures that there are multiple backups which could be used in case of loss. Note, a DVCS system can also have a centralized database (like corporate DVCS), but users access entire repositories.
Evolution of all these version control systems, stem from three core issues, tracking changes to files, providing a backup mechanism and enabling collaboration. All these issues are relevant to us as we prepare for data analysis, it’s therefore wise for us to adopt a version control system that will address this issues. Clearly, only DVCS can do all we require and therefore we shall use it.
Now we know what a version control system is, why we need it and have even settled on a version control system to use. We now need to choose one of the DVCS to use for our tutorial course.
There are at least four DVCS, these are Git, Mercurial, Bazaar and Darcs. Out of these, Git seems to be the most widely used DVCS and has an online versioning control system. Both Git and it’s online versioning systems are free hence have no cost implication just like R. Due to these reasons, we are going to use Git and it’s online host (GitHub) for our sessions. In subsequent sections of this chapter we discuss these two tools (Git and GitHub), and how to work with them from RStudio.
3.2 Introduction to Git
3.2.1 What is Git?
Git is a Distributed Version Control System. It can track changes in a file or group of files, it can also provide a backup mechanism when needed as there could be multiple similar repositories used by collaborators or hosted online.
3.2.2 How does Git work?
First tell Git which directory has file or files to be version controlled. Git will then add it’s directory called “.git” and call the directory a repository. .git is usually a hidden directory containing Git’s database and other directories and files for managing the database.
Initially, when a repository is created, if it is new, it would have nothing in it, but if it was created from an existing directory then it would have untracked files. That is because Git recognizes two types of files, tracked and untracked files. These files are called untracked as Git has no knowledge of them or what they contain; Git expects you to tell it what files to track.
When you tell Git to track a file with a command add, it would read it’s content (take a snapshot) and do some bit of calculation to generate a tracking number called SHA-1 hash. SHA-1 hash is a 40 digit hexadecimal number (numbers containing digits and letters “a” to “f”), which Git uses to store file content in it’s database. Nothing is stored or retrieved without this number, it’s therefore a core component of Git.
When a file is being tracked by Git, it means Git is aware of it’s content and when you make any changes (even adding a full stop), Git will alert you of the change so you can take another “snapshot” of the file.
At this point Git is only tracking changes in the file content, however, it is not tracking when the changes were made, who made the changes and why they made those changes. You must tell Git this information with command commit for it to store it with the (last) snapshot. As normal workflow would go, it’s most likely that you would want to work on a file for sometime taking different snapshots of the file as it progresses and then tell Git to make a note of a snapshot in terms of when it was made, who made it and why. Only when a file has been added (being tracked) and committed can you share it with others in your network or an online host.
One last but important point to note as regards Git’s working, when a file is being tracked, it can reside on one of three states, it can either be staged, modified, or committed. Staged files are all files being tracked but not committed, they are awaiting to be committed. A modified file is a tracked file with changes yet to be added. A committed file is a tracked file stored in Git database with all it’s information (when file was created/changed, by whom and why). Note, staging means tracking or added files, so when you hear the term staging area it literally means tracked file area (but technically a file containing list of tracked files). When we get to using Git, you will see these terms being used as you create files, track them, change them and finally commit them. We will also be able to tell Git which files not to track: files you do not wish to share.
3.2.3 Working with Git
We now have a pretty good idea what Git does and how it does it, we can therefore go ahead and start using it, but first we need to download and install it.
3.2.3.1 Downloading and Installation
Downloading and installing Git is easy, downloads are available from “https://git-scm.com/download”. To install, please read Pro Git - Installing Git.
Pro Git book will be our core reference book on matters Git, this book is excellently written with an easy-to-understand and non-computer-science approach. I recommend you download the entire PDF version so you can refer to it when offline.
3.2.3.2 Initial setup
Before starting, Git requires a few setup details, things like your name (or name you what Git to refer to you by) and your email address. You can also tell Git to use a preferred text editor for inputting messages (like why a change has been made) or change default colors (Git uses different colors to show different states of files). We tell git this information using git config command.
For this chapter we will tell Git our name and email address, I will let you explore other setup issues on your own as they are not vital at this point (actually, it would be good to experience default Git before making other changes).
Take note, you can use Git from a Graphical User Interface (GUI) or from a command line, for us, we will use command line and specifically Git bash for windows though it should be the same as terminal for mac. GUI might be easy to use, but it is not ideal when learning Git for the first time and certainly not as comprehensive enough. So go ahead and start your “Git bash” or “terminal”.
Introducing ourselves to Git
Let’s tell Git our user name and email.
git config --global user.name "HellenG"
git config --global user.email hellengakuruh@datamania.comWe have added “–global” to command “git config” to tell git this will be our permanent identification and therefore we do not need to keep telling Git who we are when we log or use Git. However, if at any one point we want to use a different identification, then we can pass the same command without “–global” addition.
Now let’s see if Git got that and what other default setting it has.
git config --listIt should look something like this:
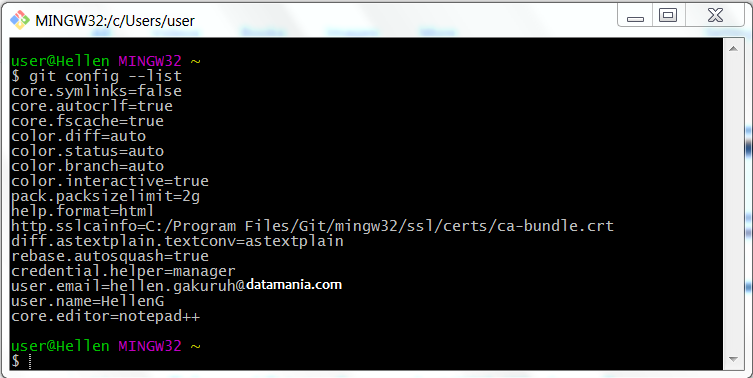
Git configuration
Now we are setup, we can start version controlling some files.
3.2.3.3 First Git Project
To start version controlling files we need to tell git which directory it’s contained in. We can start a new directory and tell git to version control files we create or tell git to version control an existing directory, possibly with a number of files. We could also get a directory that is already being version controlled by Git through a linked network like online (GitHub), basically cloning the directory.
Let’s see what happens when we start with a new or existing directory. We shall discuss cloning when we are discussing GitHub.
3.2.3.3.1 New Directory
First things first, we need to be in our working directory. Usually when Git bash starts, it will start in the “home” directory, if this is not where you want the new directory to be created, then point Git to the right direction by changing working directory with command cd (change directory). For this chapter I will create this directory in “My documents” folder.
cd DocumentsLet’s create a new directory called “learningGit”. You can create it how you usually create new directories or use command line using “mkdir” command.
mkdir learningGitNow we have a directory in my documents folder called “learningGit” for which we want to version control. We can tell Git to start version controlling the directory with git init command (it’s that easy). But first we need to be in “learningGit” directory.
cd learningGit
git init With that, git will install its “.git” sub-directory and “learningGit” will now become a Git repository (a directory with a tracking database). Git will confirm to us this has happened with an output similar to this Initialized empty Git repository in c:/Users/user/Documents/learningGit/,git/.
Do take note of the line right above input symbol “$”, there should be a (master) written after our repository name, something like this user@Hellen MINGW32 ~ Documents/learningGit(master). It is important to always be aware of this line as it tells us which repository we are working on and if it is the main repository or a branch of it. We will be discussing branching a bit later, but at this point it good to start knowing where you are; master means it’s our main repository. We will meet other branches like origin and remote later.
Now let’s see how our repository looks like using function “git status”. Remember we can have two types of files, “tracked” and “untracked” and for those that are being tracked, they can either be “staged”, “modified” or “committed”; “git status” can tell us all this.
git status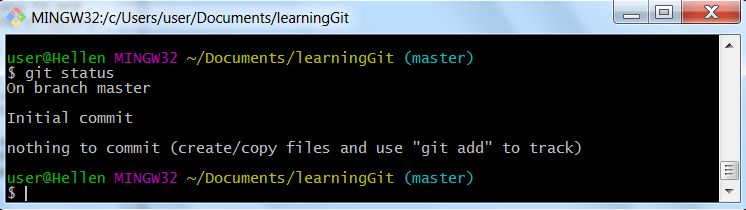
Clean Git repo
So as Git tells us, there are no files in our repository, we need to create or copy files for Git to start tracking them. Before we do that, let’s see how to version control existing directories.
3.2.3.3.2 Existing Directories
There is no difference between new and existing directories, except for new directories, we had begin by creating a directory. Otherwise for existing directories, we need to locate where our directory is and point Git to it using “cd” command before initializing the directory.
Go ahead and identify a directory (with files) you might want to version control. Here we might use different directories but we should arrive at the same output, our aim is to understand that output. Later for uniformity we will continue with our “learningGit” repository (often called “repo”) to learn how to track and commit files.
As an example I will tell Git to start tracking some of my R scripts so I will change working directory to this folder and initialize Git. It is good to know how to specify file locations, you can read this notes on files.
cd ../R/Scripts
git initLike our new directory, we have initialized an empty Git repository. What is different between our new directory and this directory is that running “git status” will output information telling us we have untracked files.
git status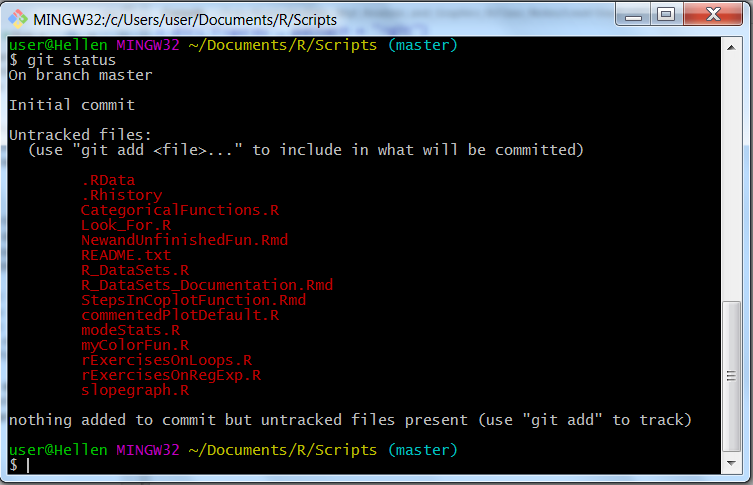
Git repo with untracked files
So let’s start tracking some files, but as agreed, let’s use our “learningGit” repo; so change working directory (“cd”) to read “learningGit”.
# For me it is
cd ../../learningGit3.2.3.4 Tracking files
Hopefully we should be in our “learningGit” repo, our Git address should be something like this.

Git address
Great, let’s create an R file, you can either open R and create a mean.R and write mean(1:10) or use command line like this:
echo "mean(1:10)" > mean.RLet’s confirm Git sees our untracked file.
git status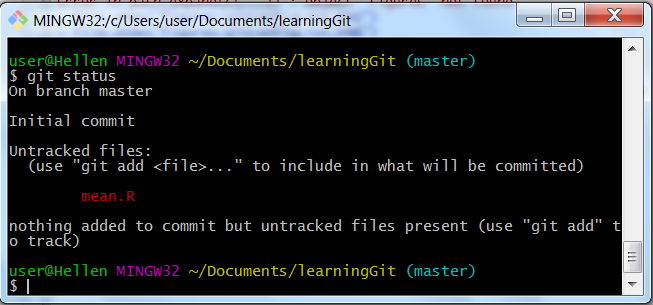
One untracked file
To tell Git to track this file or take a snapshot of it’s contents, we use command git add [file] or git add [directory]; it’s that easy.
git add mean.R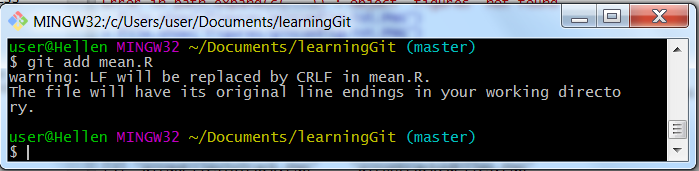
Tracking a file
If you have more that one file and you what to track all of them just say git add –a.
Now let’s see what Git has to says.
git statusGit status after stagging a file
Git now tells us it’s tracking our file, this means our file is “staged”. Now recall a staged file is one being tracked but Git has not taken note of who developed it when and why, we can only do so if we “commit the file”. That is why Git is telling us “Changes to be committed”.
Now, suppose we made changes to our “mean.R” script, what do you think Git would tell us?
Let’s see, let’s change “mean(1:10)” to “mean(1:100)”.
echo "mean(1:100)" > mean.R
git status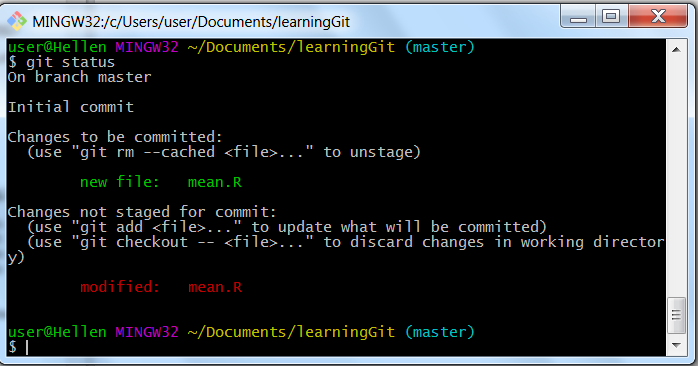
Git status after change to a staged file
Git says we have one file at different states, we have it at “staged” state and “modified” state. What this means is that Git is aware that our file has changed since the last time we “added it”. Here we can go ahead with the changes by re-adding the file or asking Git to add the new changes or discard the changes altogether. As Git tells us, we can discard the changes by running the command git checkout mean.R, but let’s assume we made the correct change and ask Git to recognize it. So we run “git add” again and see what Git says.
git add mean.R
git statusNow Git says all is fine, we just need to commit our changes.
3.2.3.5 Commiting
To commit a file, it’s as easy as git commit -m “[commit message]”. A commit message can be anything from the widely used “Initial commit” to “Draft one of some file”, basically this message should be a small informative communication of what the file is or changes made to it.
git commit -m "Initial Commit"Let’s see what happens when we do “Git status”.
git status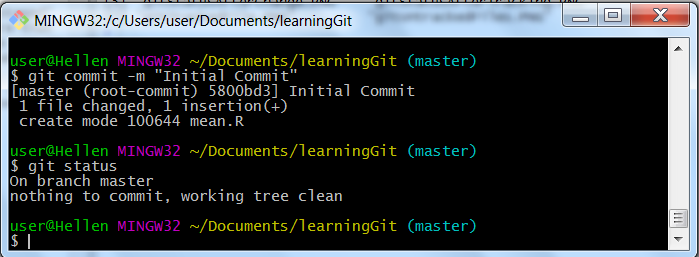
Git status after committing file
Git tells us we have stored everything, there are no untracked files or files in our staging area.
3.2.3.6 .gitignore files
Suppose we have files in our repository we don’t want Git to track, for example program files or files we don’t want to share. We can tell Git not to track these files by listing their names or pattern in a file called .gitignore. Yes, this is a file extension without a name, but interestingly it is a text file so you can open with any text editor including R’s text editor (where we write our scripts).
Before we create this “.gitignore” file, let’s do a “before-and-after”. That is, let’s create a file we don’t what tracked, see how thing are with “git status”, then create our “.gitignore” file and see what happens with “git status”.
Okay, let’s say we don’t want to track any word document or files ending with “.docx” since they might be report documents. We can then create one word document called “Report1.docx” with a one liner “Report 1” and follow-up with a “git status”" to see how things are.
git status 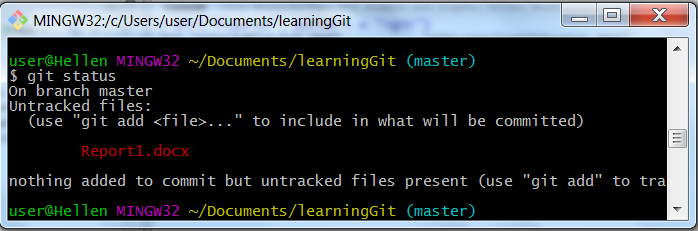
Git status when a .docx file is created
Git sees our word document and tells us it has not started tracking it. Now let’s tell it to ignore it and any other word documents we create later.
We are going to create our “.gitignore” file on the command line as Windows will not allow us to create a file with only an extension for a name. Command to create a file is touch followed by file name.
# Make sure you are in our repository which is our working directory
touch .gitignoreNow we have “.gitignore” as a new and untracked file in our repository but it is currently empty. We therefore need open this file and add a list of files to be ignored, in this case any word document. We can open the file with any text editor like notepad, notepad++ or even R, then write “*.docx“, which means any file name ending with a”.docx" extension. I suggest we use R as our text editor like this:
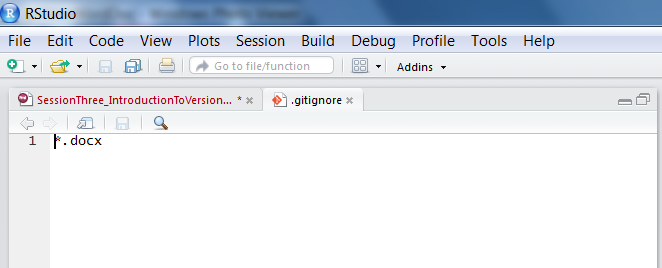
A .gitignore file
Now let’s take a look at our repository.
git statusGit is now not telling us we have one untracked file, that is our “.gitignore” file.
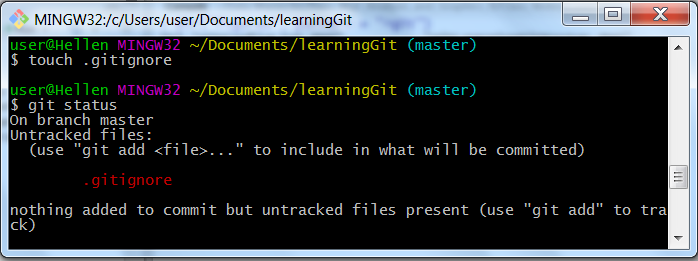
Git status when .docx is added to .gitinore
With that, we know any word document created will not be listed as untracked document. You can confirm this by adding another word document and check with “git status”. But right now, let’s have a clean repo by tracking and committing our git ignore file.
We can tell Git to track and commit our file with one command like this“”
git commit -am ".gitignore version 1"“-am” are two flags meaning add (for tracking) and message (for committing).
At this point we have all the basic skills needed to version control with Git, but let’s venture a little bit into something Git is renown for, that is branching; version control has never been the same after inclusion of branches.
3.2.3.7 Creating, Merging and Deleting Branches
When we start doing data analysis we are bound to create our own functions, in the process, we might initially have functions that we consider stable, they might not be perfect or complete, but they work. At this point we may have other ideas of making the function better or completing it but might be scared to use our original script in case we introduce bugs. Ordinarily we would make a copy of our script and make amendments to it and only including the changes when we know they are sound.
With Git, this is now not a problem as Git gives us an opportunity to open branches where we can make our changes and only merging with main branch when we are done.
So how does Git do branching?
3.2.3.7.1 How Git Implements Branching
When we create a Git repository, Git automatically assigns for us a “master branch”, this branch would contain our original commit history (files stored in our Git database). Creating a new branch means Git has created a file with a pointer to our original branch “master” or database. A pointer is 40 hexadecimal character string we called “SHA-1 hash”. So when we switch to our new branch, because of this pointer, our new branch will have the same commit history as our master branch (it would be like a duplicate).
From that point on, since Git allows moving between branches, commits become different. As commits are made in either branch, their paths become parallel to one another. One more interesting thing with Git, we can create more branches from master or any other branch. So it is possible to have multiple branches with different commit history after initial branching. The whole idea behind this multi-branching is to allow branching to test small sections which are merged and discarded as soon as it is considered stable or complete.
With this basic idea, Git makes creating, merging and deleting branches as easy as possible as long as there are no merge conflicts. Merge conflict mostly occur when two or more branches change the same file and section. When this happens Git is unable to do a clean merge and will ask us to resolve conflict before merging.
Git keeps track of what branch we are currently working on by noting it’s pointer in a file called HEAD. HEAD will change with each branch movement, for example, if we are working on our master branch then it’s the current HEAD, but if we are working on a new branch, the new branch is the HEAD.
That’s about how Git does branching (at least without going into technical details of Git’s internals, I leave you to read chapter 10 of Pro Git ). For now let’s have a go at Git branching to see how it can make our analysis fun and easy.
3.2.3.8 Using Git Branching for Function Development
Suppose we want to develop a function that will search for certain files in our system, read it’s content and tell us which files contain a certain pattern. Let’s also suppose that we have developed the first part of the function (search for files with a certain pattern) and saved it under the name myGoogler.R. Here’s the code,
# Open R, type and save this code and then close the file
look.for <- function(pattern, directory = ".", ...){
list.files(path = directory, pattern = pattern, all.files = TRUE, full.names = TRUE, recursive = TRUE, ignore.case = TRUE)
}We are going with the premise this part of our function works, we however don’t what to proceed with function development least we break our function. So we decide to create a branch, but before that, we need have a look at how things are in our master branch then proceed to stage and commit our new file.
git status
git add myGoogler.R
git commit -m "Initial commit for myGoogler.R"Now let’s confirm our master branch has our last commit. Command git log is used to view commits made in a given branch like our master branch, options can be added to control what and how it is shown. For us we want something easy to read so we use options –oneline for “pretty printing” and –decorate to print only a portion of commits reference numbers (the 40 hexadecimal numbers we discussed earlier).
git log --oneline --decorateYou should see something like this:
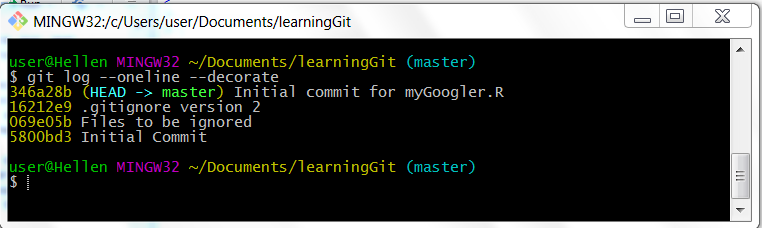
Git commit log
The first numbers you see are hash numbers (at least part of the 40 hexadecimal number) for last commit, we know it is the last commit as the message is the last we typed. Also note HEAD is pointing to master so we know we are in our master branch. Below this are three other numbers representing three previous commits. You see, Git never forgets what you commit, you can actually use this commits hash numbers to restore a previous commit or reverse files to a time they were committed.
Now that we know our “myGoogler.R” file is tracked and committed in our master branch, we can create another branch to work on the file without risking our original file.
We create a new branch with command “git branch” followed by a branch name, we will call this branch matchPattern. After creating it, we need to move into that branch with command git checkout [branch name]: This command is used to switch between branches. When we are in our new branch we can ask Git to give us a summarized picture of our new branch with our “Git log –oneline –decorate” command.
git branch matchPattern
git checkout matchPattern
git log --oneline --decorate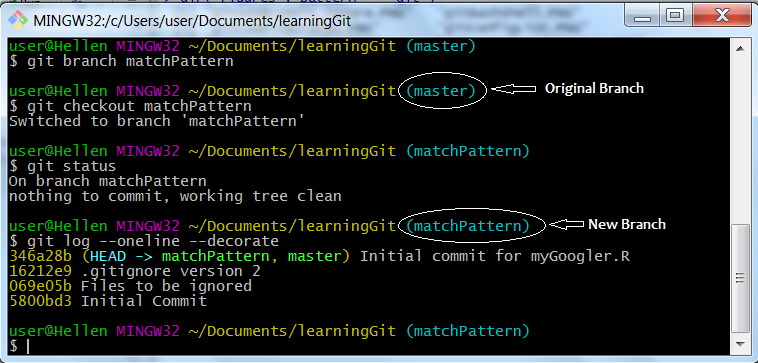
Git branches
If you look closely, you will notice last commit number (first after our git log command) is the same as our master branch that is 346a28b and there are two branches “matchPattern” and “master” but HEAD is pointing to “matchPattern”. So everything is exactly as our “master branch” with the exception of additional branch and where HEAD is pointing.
Now open our “myGoogler.R” file and add the following code (close file once done). Let’s assume it’s some good progress to our mission but it is not yet done.
readMatch <- function(x, pattern, ...){
n <- length(x)
lapply(1:n, function(i) {
content <- readLines(x[i])
grep(pattern, content, ...)
})
}As we are working on this little project of ours, we receive some comments on our first function and there is something that needs to be amended right away. So we pause development of our second function and we decide to correct our first function. But since our current branch “matchPattern” has been modified, Git will not allow us to switch branches (go back to master branch) without committing these changes, we therefore need to do this before switching.
git status
git add myGoogler.R
git commit -m "Added readMatch function"
git log --oneline --decorateIf we ask Git to print for us our current status in our new branch, we should see this:
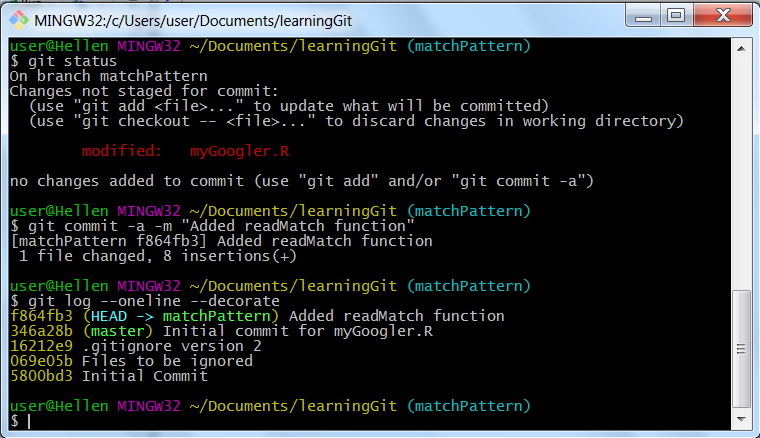
Git status on new branch
We have a new commit f864fb3 in our current branch (HEAD - matchPattern), this is ahead of our “master branch” 346a28b. Let’s go back to master branch and confirm “matchPattern” is one commit ahead of master. Remember, command “git checkout [branch name]” is used to switch between branches and “git log –oneline –decorate” to give us a pretty summary.
git checkout master
git log --oneline --decorateWith these commands, you should see something like this:
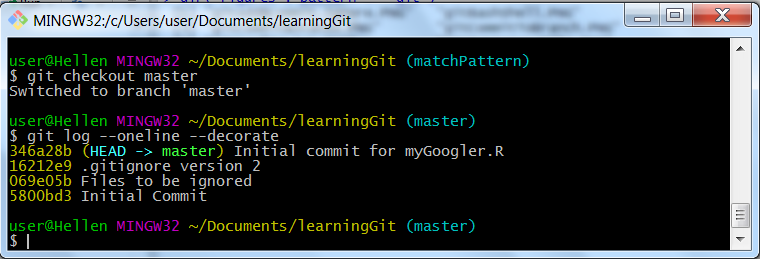
Git status on master branch
Our HEAD is now pointing to master and commit is still at 346a28b as shown from our “master branch”. What this means is that whatever changes “matchPattern” branch made to our file are not reflected on our file; confirm this by opening our “myGoogler.R” file. Don’t worry, Git has not lost our changes, we will get them in good time.
For now, let’s assume what we have received as regards our original code might need some testing, so we create another branch called fixDefault to try it out before we introduce this change to our original code.
Okay, how about a short version of creating and switching to a new branch all in one line of code. So instead of saying “git branch [New branch]” and “git checkout [New branch]”, we say:
git checkout -b fixDefaultWe are now in our new branch “fixDefault” which has the same commit history as our master branch (meaning it does not have changes made in “matchPattern” branch).
Now open our “myGoogler.R” file and change directory default to “~” or replace “look.for” function with this one:
look.for <- function(pattern, directory = "~", ...){
list.files(path = directory, pattern = pattern, all.files = TRUE, full.names = TRUE, recursive = TRUE, ignore.case = TRUE)
}Super, now let’s assume we have tested the function and it works, no bugs. We therefore want to merge this branch with our master branch. To do so we need to be in our master branch, but we cannot do so if we have a modified file, we need to stage the changes and then commit it. So let’s do so and ask Git to give us a picture of our new branch.
git status
git commit -am 'Changed default for argument "directory" in function "look.for"'
git log --oneline --decorateThis is what you should see:
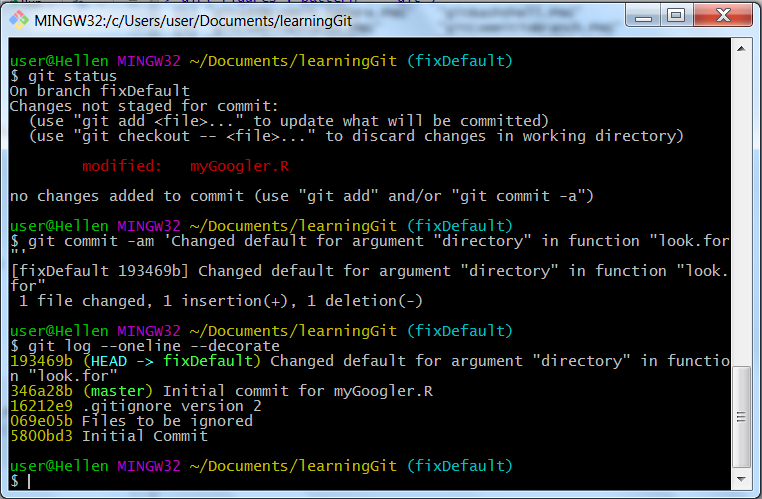
Git commits to second branch
We are definitely one commit ahead of master, as last commit is 193469b while master is 346a28b. We can diagram this commit progress like this:
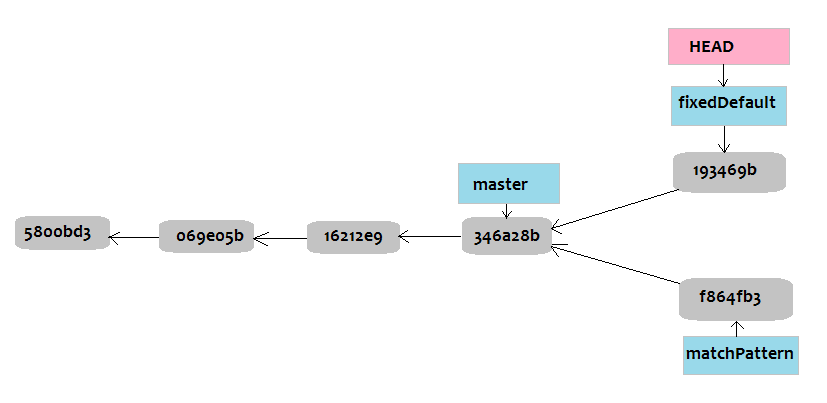
Git commit progress
From our diagram, HEAD points to “fixDefault” branch which is our current branch. At this branch we are at commit “193469b” and it’s previous commit is “master’s” last commit, that is “346a28b”, and the others are commits made earlier. We can also see from our other branch “matchPattern” we are also one commit ahead of master as it is at commit “f864fb3”. Note, arrows are pointing backwards to an earlier commit as each commit always takes note of it previous commit, this previous commit is it’s parent commit and ensures continuity and trace-back of commits.
Now let’s switch to master and merge using command git merge [branch].
git checkout master
git merge fixDefaultThere we have done it, with just one line of code we have moved our master branch one commit ahead (fast-forwarded master branch). This is what you should see on Git Bash or Terminal:
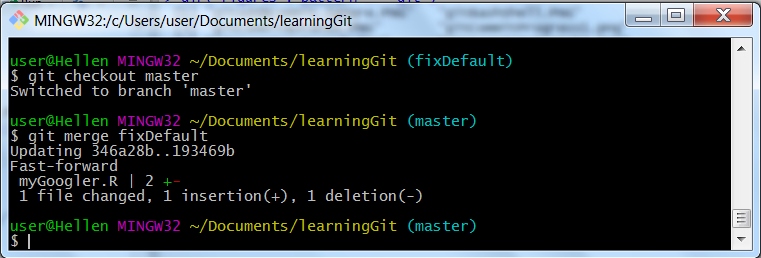
Git merge
Since our master branch has the same commit with branch “fixDefault”, that is, what changes we made in “fixDefault” are now reflected by “master branch”, we can safely delete “fixDefault” (it’s work is done). To delete a branch, just use “git branch” command with a “-d” flag before branch to be deleted. Something like this:
git branch -d fixDefaultOkay, with that issue sorted, we can go back to “matchPattern” and finalize what we had started.
git checkout matchPatternNow let’s assume the only change needed for our function was a simplified return vector, which we do so like this:
# Replace earlier function with this
matchPattern <- function(x, pattern, ...){
n <- length(x)
m <- lapply(1:n, function(i) {
content <- readLines(x[i])
grep(pattern, content, ...)
})
unlist(m)
}With that done, we can add and commit our changes before going back to master and do a merge. Here we will use a short form of “add” and “commit” by combining “-a” and “-m” flag (Not a good practice, but it’s good to know it can be done). We also ask Git to give us status of our current branch.
git commit -am "Changed return object"
git log --oneline --decorateThis is how our branch commit history looks like:
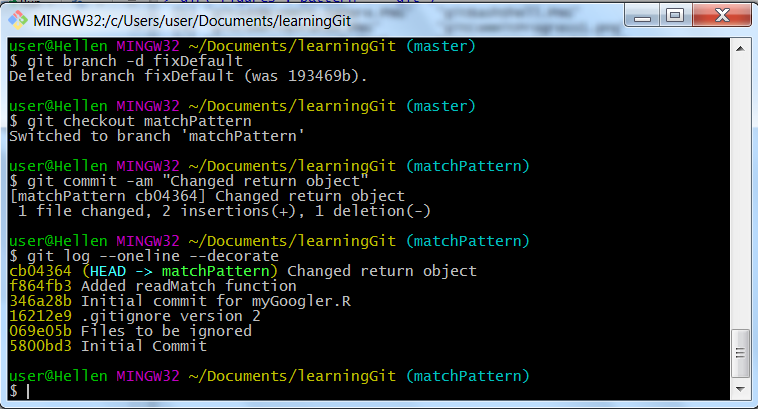
Git commit to a branch
We have certainly moved ahead, actually this branch “matchPattern” is two commits (cb04364 and f864fb3) ahead of master when it was at commit 346a28b.
We can show our commit history with this diagram:
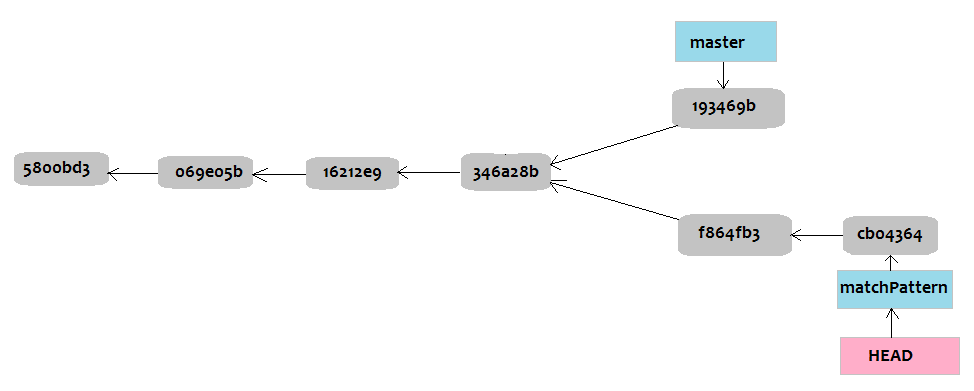
Git commit progress
Notice master is now one commit ahead because of the merge we did, that is, the fast-forward we made by taking “fixDefault’s” last commit which was 193469b. When we ask Git to merge “matchPattern” into “master” it has to look at the changes made in “matchPattern” and those of commit “193469b”, if changes were made to different sections of the file, then Git can make a clean merge, but if changes were made in the same section (like in the same function), then Git will tell us there is a merge conflict for which we have to resolve before merging. Resolving basically involves looking at the changes made to the conflict section and deciding what change is correct or how the changes can be unified. This process can be quite messy if not well done and that is why it is important to be aware of what sections are being worked on before doing a merge.
Lucky for us we were working on different sections and Git should be able to do a clean merge or what is called a basic merge. Therefore let’s checkout master and merge.
git checkout master
git merge matchPatternIf everything went well you should receive an output with the first line reading Merge made by ‘recursive’ strategy. This line is Git’s way of telling you it had to so some extra work to merge “matchPattern” into “master”. This is because unlike earlier match, “master” is not a direct parent of “matchPattern” since we fastforwared it. Therefore Git had to look at “master” branch at current commit and “matchPattern” and compare to their common ancestor (master’s earlier commit) before doing a merge: This called a simple three way merge.
Now, for learning purposes, look at my output:
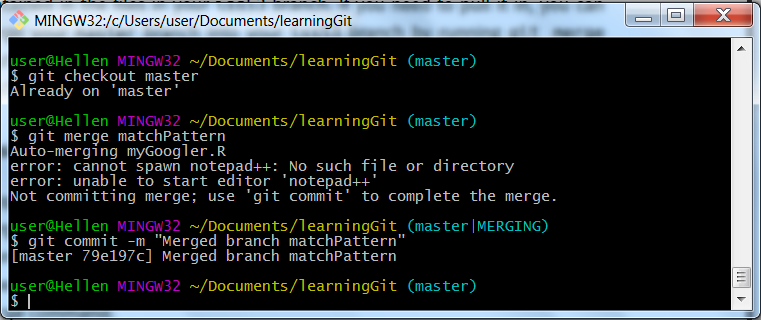
Git second merge
I have two issues here, one, I checkout master twice and Git politely tells me I am already on branch master. Second, when configuring Git, I set my editor to notepad++ simply because I like the editor, but did not do it correctly, therefore Git get’s back to me saying it can’t get an editor for me to input my merge commit message.
To address my editor issue, I resulted to going back to Git’s default editor called vim, it’s not as easy as R’s editor or my preferred notepad++, but it is what Git uses. So I changed my text editor’s configuration with:
git config core.editor vimA bit about vim
Vim has two states or modes, one is insert mode and the other is command mode. When Git you takes you to this editor to input some message, use insert mode by pressing i, type in you message and then go to command mode by pressing esc. From here you can save your message and exit vim by pressing :wq the enter.
If you what to learn more about vim, read this and this articles, these are two of the few documentations that are summarized and easy to understand about using vim. If you want to know how it came about and how it’s used, read this Wikipedia page.
Now that we have successfully merged “matchPattern” into our master branch we can now delete “matchPattern” branch.
git branch -d matchPattern
git branch # This should show we have only one branch *masterWith that, we have skills to create, merge and delete branches. We also know how merge conflicts can occur and how to pre-empt them. Now let’s see how to get help in Git.
3.2.3.9 Getting help
First thing before getting help with Git or any programming language is to get the basics right, in Git it would be good to read Pro Git, this is an excellent read and chapter one and two should cover the basics. You can also take one of GitHub’s courses from their online training site.
With the basics covered, to get help with any of Git’s command use any of the following commands:
git help [command]
git [command] --help
man git -[command]>For example we can ask for information on “branch”:
git help branch“git help” is available even offline, so it is quite convenient.
Other sources of help are online Q&A forums like Stackoverflow, GitHub/Gist repo’s like https://gist.github.com/zachallaun/436ec0a88b36bbfd5002*, cheat sheets like https://gist.github.com/zachallaun/436ec0a88b36bbfd5002*, or training blogs like *https://www.codeproject.com/Articles/457305/Basic-Git-Command-Line-Reference-for-Windows-Users*.
3.3 Collaborating with other R programmers/developers
One of the core issues with version control is ability to collaborate with other people. Collaboration means being able to share our repositories or get another repository and being able to work seamlessly to achieve a goal.
By now you know Git is a local version control system, that is, everything happens in our computer, however Git has the capability of working with other networks including online in order to create a collaboration platform. For this chapter we will look at how to collaborate with other R programmers/developers using GitHub which is Git’s largest and most popular online host.
3.3.1 Working with remote repositories: GitGub
GitHub is the place to be as a budding programmer or developer, you will not only share your code for insights from other programmers or developers in your language (like R), but you can learn from others by looking at their code.
There are two types of account in GitHub, a free account and a premium account. A free account is sufficient to start to collaborate with others, the only thing to note is that all free accounts are public accounts, anyone with or without a GitHub account can access your repositories.
We are going to create a free account but with a caveat that everything shared is in public domain so we must make sure to use “.gitignore” for file that we do not want share.
3.3.1.1 Signing up for a GitHub Account
To signup for the free GitHub account:
- Go to https://github.com
- Click Create your personal account, then type a username (preferably the same as what you gave Git, if it’s available), then your email address (don’t worry, GitHub will not display it if you do not want it to, but must be working), add a password and then click Create an account.
- Select account plan as Free account and finally
- Click Finish sign up
- One last step but very important, verify your email address
… and you are done, you are now a GitHub account holder (your GitHub address should be **https://github.com/[username]**). If you want a visual on this, checkout this YouTube video: How to Create a GitHub Account. A Quick look by GitHUb Training & Guides.
3.3.1.2 Hosting/Sharing local repository (Git) on GitHub (remote repository)
The first thing we might want to do is upload one of our local repo’s online as a backup or a share mechanism. As an example of how to host/share a local repo’s online, let’s use our “learningGit” repo.
Since our GitHub account does not have “learningGit” repo (or any other repo if you have just signed up), we will start by creating an empty repo (not entirely, we want to sweat a bit, you will see why in a short while) which we will use to push our local repo.
Let’s go through this step by step:
Initializing a GitHub Repository
Step 1: We start by locating and click the + sign (located on the top right hand side below the address bar), we then click New repository.
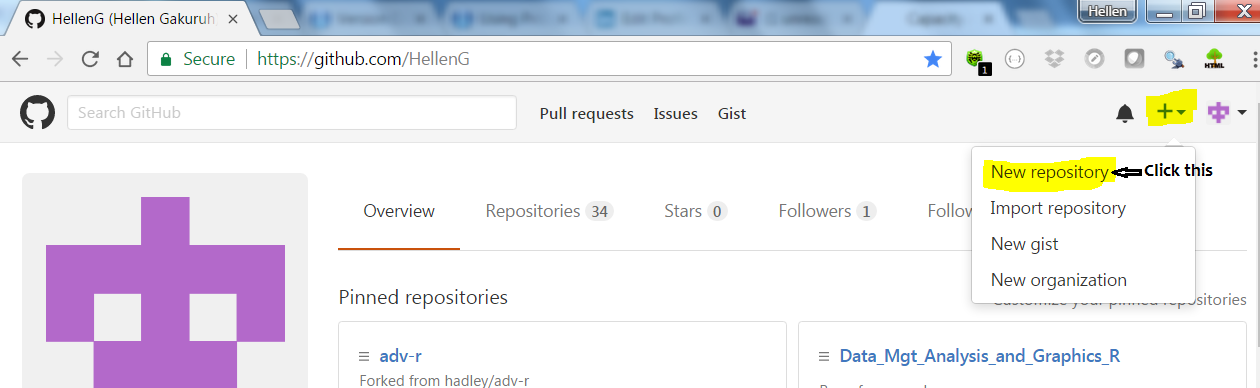
Creating a new repo on GitHub
Step 2: We fill GitHub’s form:
- First thing we fill is our repo’s name that is learningGit
- Next a description for our repo as Repo for Introduction to Version Control using Git and GitHub Training Session (although anything else would have been just fine).
- On whether our repo will be public or private, leave it as Public as all free GitHub account have to be public.
- Next we click Initialize this repository with a README file. A README file is a basic text file documenting a repository. This is an important file to have in any repo. However, it is not good for us to initialize this repo with any file if we want a smooth upload from our local Git, we will discuss this as soon as we have created our remote repository.
- The bottom two buttons are not necessary as we have already created a “.gitignore” file in our local repository and we are not sharing any licensed files.
- Finally we click Create repository and we are good to go, we now have an online version of our learningGit repo.
At this point GitHub will take us to our repository which will have the following address https://github.com/[username]/learningGit and look something like this:
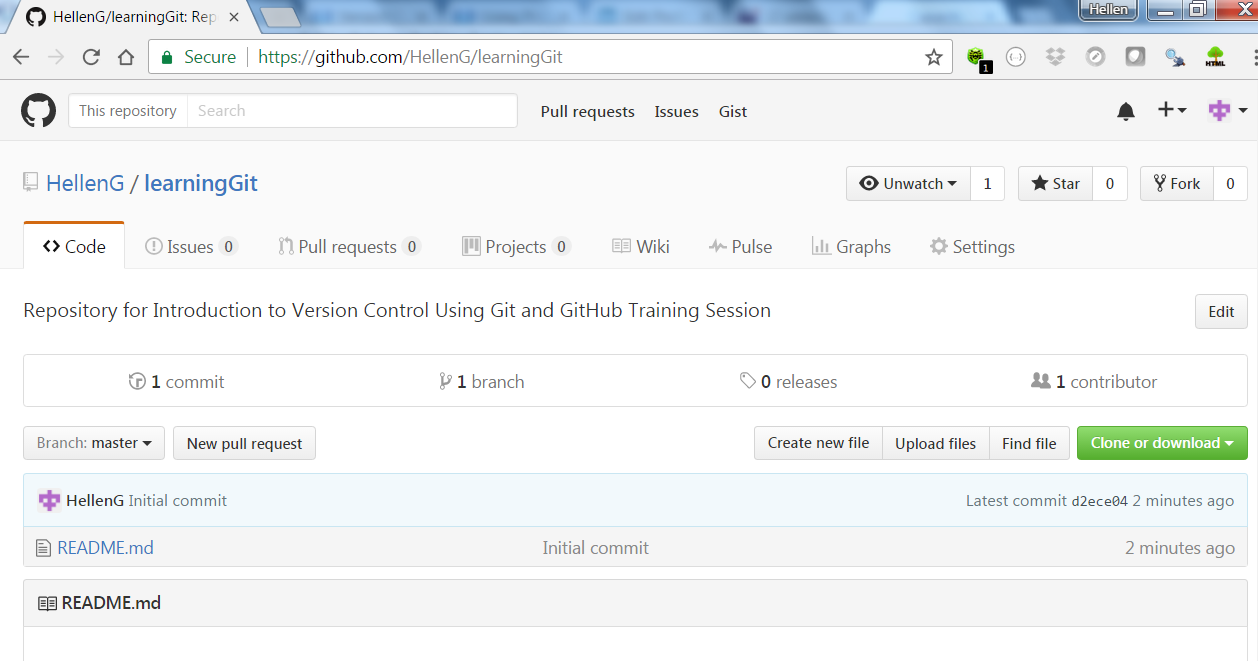
“learningGit” repo on GitHub
Great, good progress, we can now upload our files to our GitHub page, something referred to by GitHub as pushing. In very simple terms, making a “push” means uploading tracked and committed files on our local Git to a remote repository.
To make a push, we must direct Git to a remote URL we what to push to. This can be one of our own GitHub repository or another repository we have push access (a repo we are listed as contributing collaborator). Either way, we can only make a “push” (upload committed files) if our local repository is ahead of the remote repository we are committing to. Basically, we should have more files or a file with commits ahead of remote branch. If remote branch is ahead, or has a file(s) we do not have on our local repository, then GitHub will not allow us to make the “push”. The basic reason GitHub disallows this “push”, is to allow the person pushing to be aware of the files or changes made to a remote before pushing. This way, GitHub prevents duplication or file conflicts.
Now recall we initialized our remote with a “README.md” file, well, we don’t have this file locally, so GitHub will not allow us to do a clean “push”; this is what I meant by us breaking a sweat or two (in the learning spirit). To resolve this little challenge, we need to tell GitHub to download (or what GitHub calls pull) our remote repository for us to merge with our local repository. The command we use to pull from remote is git pull [remote] [local], however, if we ask Git to do a plain “git pull [remote] [local]”, we will receive a message saying our local repo and our remote repositories have different histories. In deed they do, think about it, how many commits do we have on our local repo (certainly more than 1) and how many do we have on our remote, well, just one, so Git is spot on. Since in our case this history difference has no impact as our current interest is to pull in the one file we do not have, then we can tell Git to overlook our repo’s histories. Of course, if we were collaborating with other people we would certainly not want to overlook their histories, this would require us to take a different approach, but that’s more of advance GitHub, for now let’s learn the basics (nothing like a good solid foundation).
Once we have asked Git to overlook the histories, GitHub will see the main difference is README file and therefore add to our local repository and ask us to make a commit message before storing it in our local repo. After that we can safely push our local repository to our remote repository.
Here’s how our GitHub repository looks like before “pushing”:
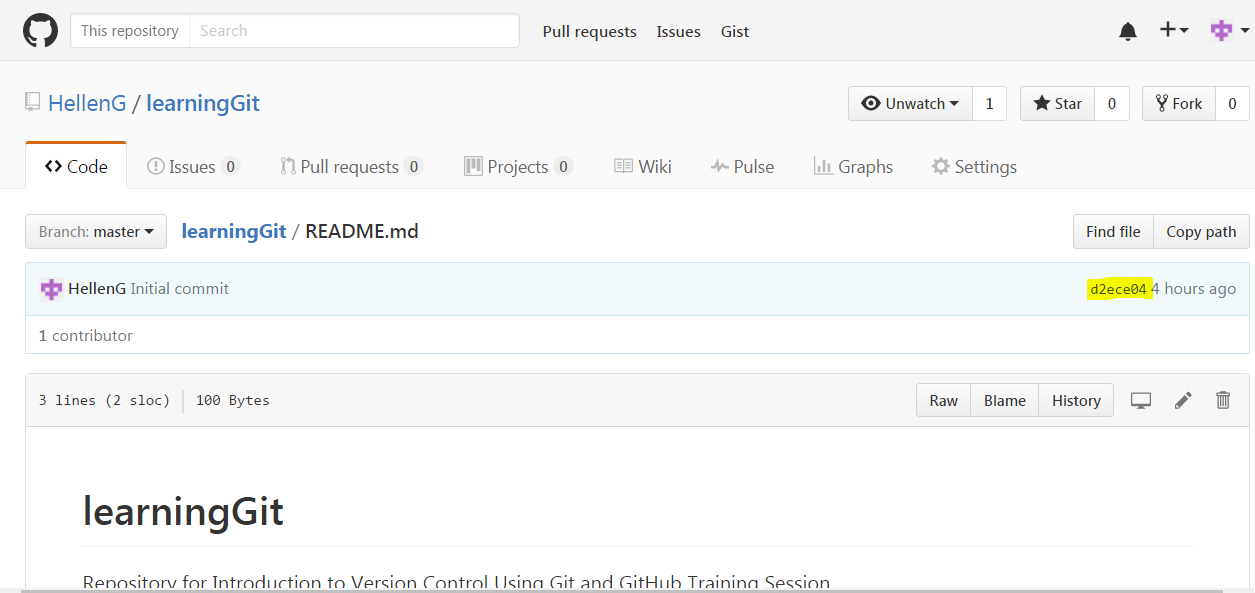
GitHub README commit
Everything we have discussed above can be summarized into three actions for us to successfully “push” our local repo to our remote repo; these are adding a remote, pulling and then pushing. Let’s discuss them step wise:
Pull and Push
Step One: Add a remote
We begin by telling Git our GitHub’s repo URL. We do this by typing command git remote add [name] [url] in Git bash/Terminal while at our working directory or repository. We can view remotes listed for any Git repo with git remote -v.
git remote -v
git remote add learningGit https://github.com/HellenG/learningGit
git remote -vThis is how our Git bash/Terminal looks like:
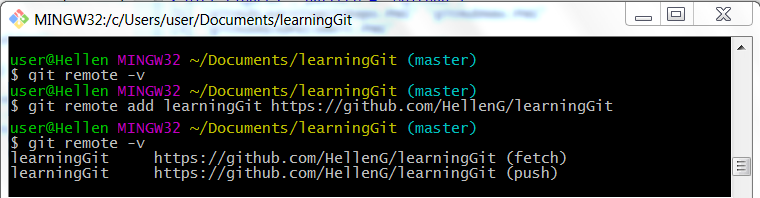
Step Two: Pull, but overlook history
Now that Git knows where to pull and push, we can pull committed files in our GitHub repo, remember we have to tell Git to overlook local and remote histories.
git pull learningGit master --allow-unrelated-histories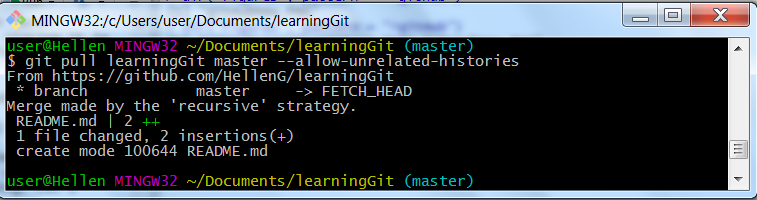
Git pull with unrelated histories
Do note, command “pull” is a combined command for “fetch” and “merge”. That means “pull”, downloads all committed files in remote and merges them with local repository. We could have easily done a “fetch” and then a “merge” but pull is sufficient for this purpose, but if we wanted to review changes before merging, then we would have used git fetch before git merge.
Step Three: Push while setting upsteam
With a successful “pull”, we now have everything our remote repository had which is basically a “README” file, therefore we can now “push” our local repo to our GitHub repo. Since this is our first “push”, we need to add this push URL as our upstream URL, otherwise for subsequent push will do a “git push” without mentioning “upstream”.
There two interrelated term we need to be aware of as we make any push, these are upstream and origin. For now I want us to hold discussion on these two for awhile, at least until we are about to clone a repo; only then will we be able to make a good distinction between the two.
Back to our current “push”, we can start by checking we have a “README.md” file by running “ls” (list files) command and then running git push –set-upstream [remote] [local] command:
ls
git push --set-upstream learningGit masterWith that, we can say we have successfully pushed to our GitHub repository.
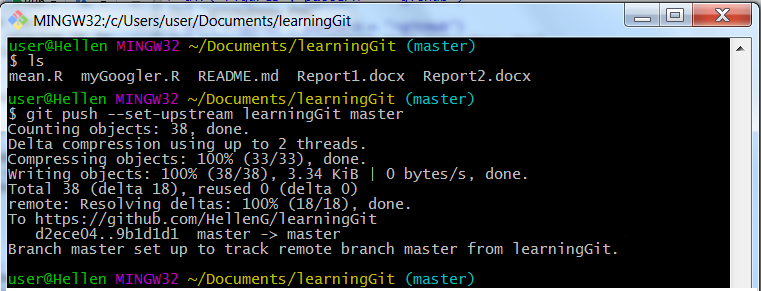
Push to upstream
Go ahead and check your GitHub repository, do you see “.gitignore”, “mean.R” and “myGoogler.R”, if so, then we have been successful.
It is good to mention we didn’t have to do a pull had we initialized our GitHub repo without a “README.md” file. We could have also done away with “pull” had we began by initializing a GitHub repository then cloning it locally rather that starting with a Git repo as we did. This two scenario’s would certainly have been easier, but where is the fun in that and we could not have learnt how to deal with the issue.
Now let’s discuss how to bring in (localize) a GitHub repository.
3.3.1.3 Downloading a GitHub repository
Other than hosting or sharing our local repo, we can recreate a GitHub repository locally. This can be one of our own repository or another public repository (you do not need to ask permission to recreate a public repository).
GitHub calls recreating a repository as cloning which literally means getting an exact copy of the original. If the repo we wish to clone is another public repo (not one of our own), then we will need to recreate it in our GitHub account before cloning it locally. The term used to recreate another public repo in our GitHub account is fork. If the repository is one of our own, then we only need to “clone” it.
As a learning practice, let’s clone another public repository, that way we can easily clone our collaborators repo’s. As an example, we are going to clone Professor Roger Peng’s repository with Data Science materials, we want to have a local copy of these files. Maybe after reading some of these files, if you are not enrolled to Coursera Data Science Specialization, then you might consider enrolling, it’s an excellent course.
Forking and Cloning a Repo
Open https://github.com/rdpeng/course, and on the top, somewhere on the right hand, locate a button written fork, and click it.
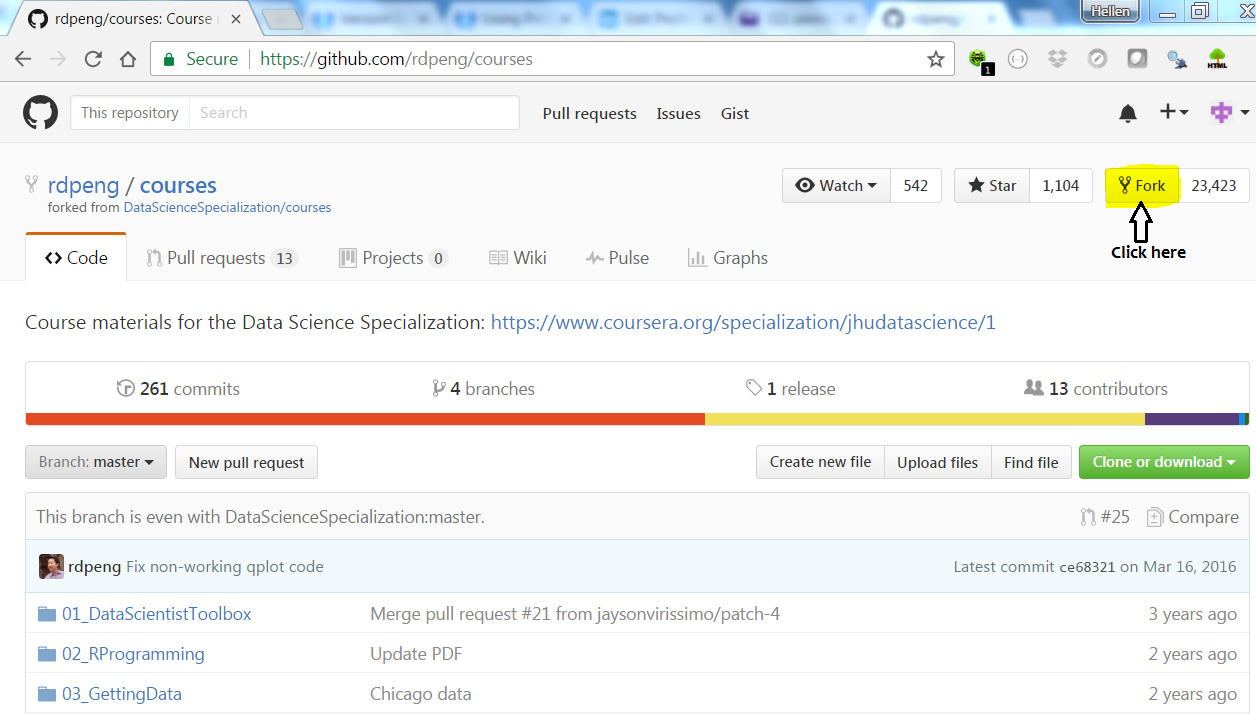
This should immediately create a copy of the repository in our GitHub account. GitHub will open this new repository with a URL similar to https://github.com/[username]/courses.
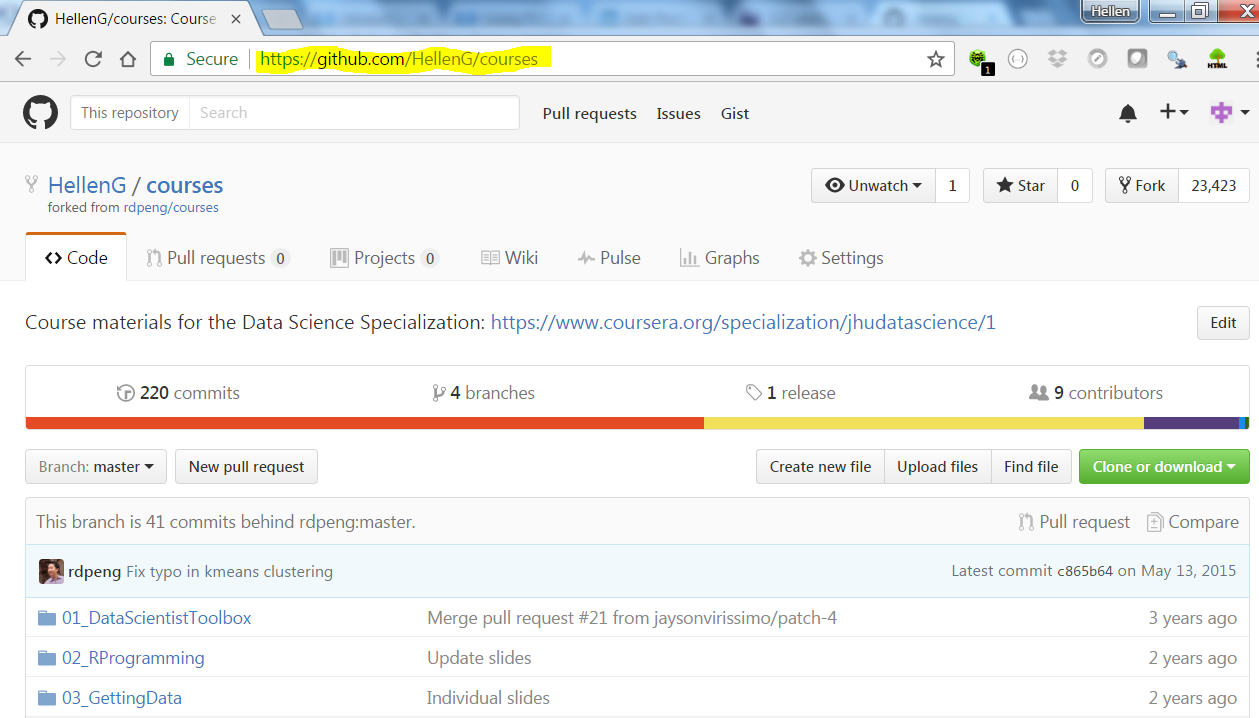
Forking a public repo
To clone this repository locally, we use the command git clone [url], but we must make sure we are in the directory we want this repository to be located.
cd Documents
git clone https://github.com/HellenG/coursesThat’s it, we should have a local copy of this repository in our computer. Note, it is already a repository so we do not need to do a “git init”.
Now that we have been able to clone “course” repository (made it available locally), let’s revisit our earlier terms upstream and origin. In the context of pushing cloned repositories we forked, the URL from which we “forked” the repo is called an “upstream” while our GitHub copy is called “origin”. It is important to distinguish these two terms as sometimes we might need to create separate push and pull remote handles (URL). That way we can push or pull to either one of the repositories. That is, we can either push to our own repo or if we have collaborator rights, we can directly push to the forked repository.
There are many other things to learn as far as Git and GitHub are concerned, things like rebasing (re-writting history), tagging (marking important points in history like release commit), creating Git aliases, Git on the server, GitHub’s two factor authentication and much more. However, the basic idea of an introductory session is to break the ground figuratively speaking. We want to get the basics right, implement them and then learn some more as we work with both tools. So that’s enough for an introductory session, now let’s see how to version control while using RStudio (our Integrated Development Environment - IDE).
3.4 Using Git and GitHub in RStudio
RStudio has made version controlling files very easy, we just have to start with an RStudio Project. RStudio projects is platform on RStudio where a collection of different work can be managed together even though they might have different working directories, workspace, history and source documents.
We can create an RStudio project from a new directory (with nothing in it), an existing directory (with files), or clone a version controlled repository.
As an example, we are going to convert our “learningGit” repository into an RStudio project, that way, we can stage, commit and push files right in RStudio without using Git bash or Terminal.
To turn “learningGit” into an RStudio project, click File then New project and from the pop-up window click Existing Directory. Locate where you have saved your repo using Browse and click Create project and RStudio will open a new session in your new project. Something like this:
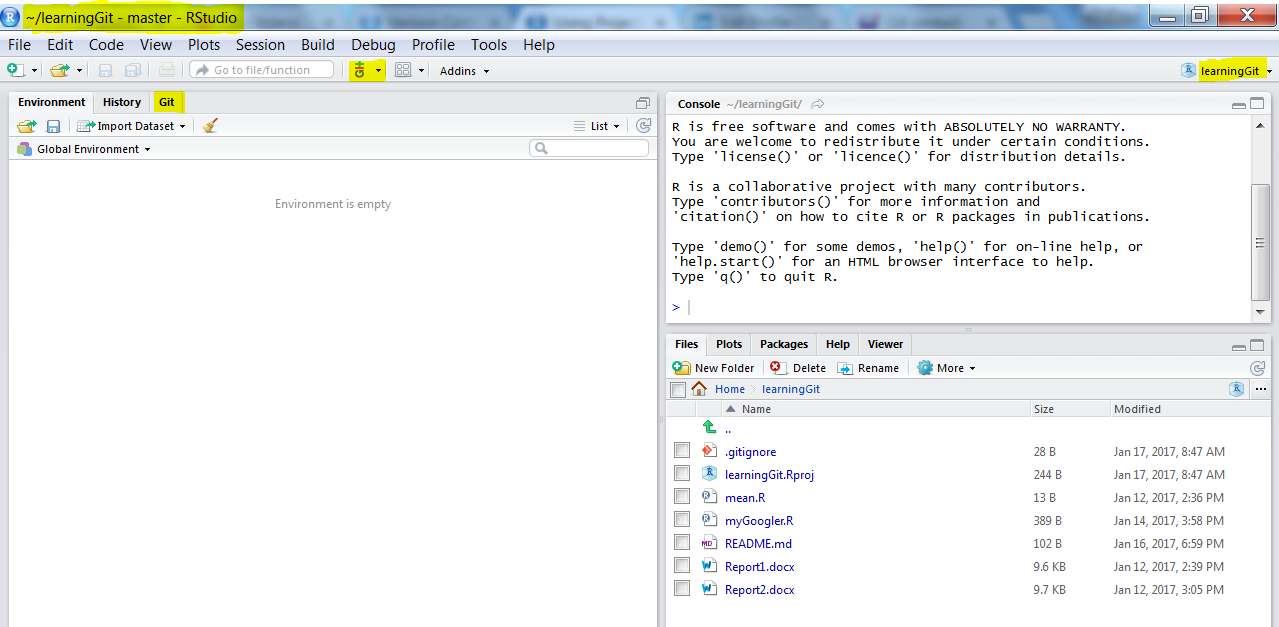
Version Control on RStudio
Now let’s see how super easy it is to add, commit and push a file. Let’s create a new file in R, we can call it newscript.R and save it. This is how our project looks like with the new file:
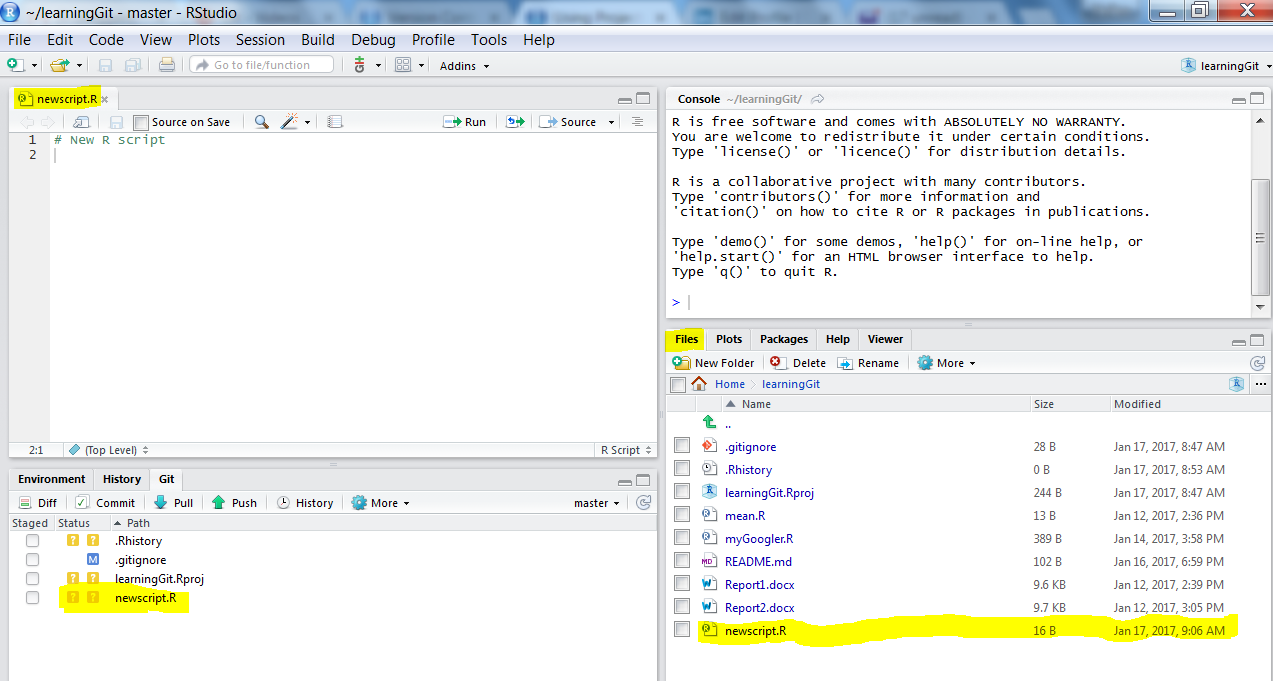
RStudio’s pane showing version control
My RStudio layout is different from default layout (I changed it to be able to write on one side and view console on the other side), but you should have the same pane’s. From Git pane next to environment and History, do you see some question marks next to some files, this means these files are not being tracked, for our new file, click the Staged check box and click Commit located just below the pane’s bar. A new window will pop-up, type in a commit message on the right hand side like this:
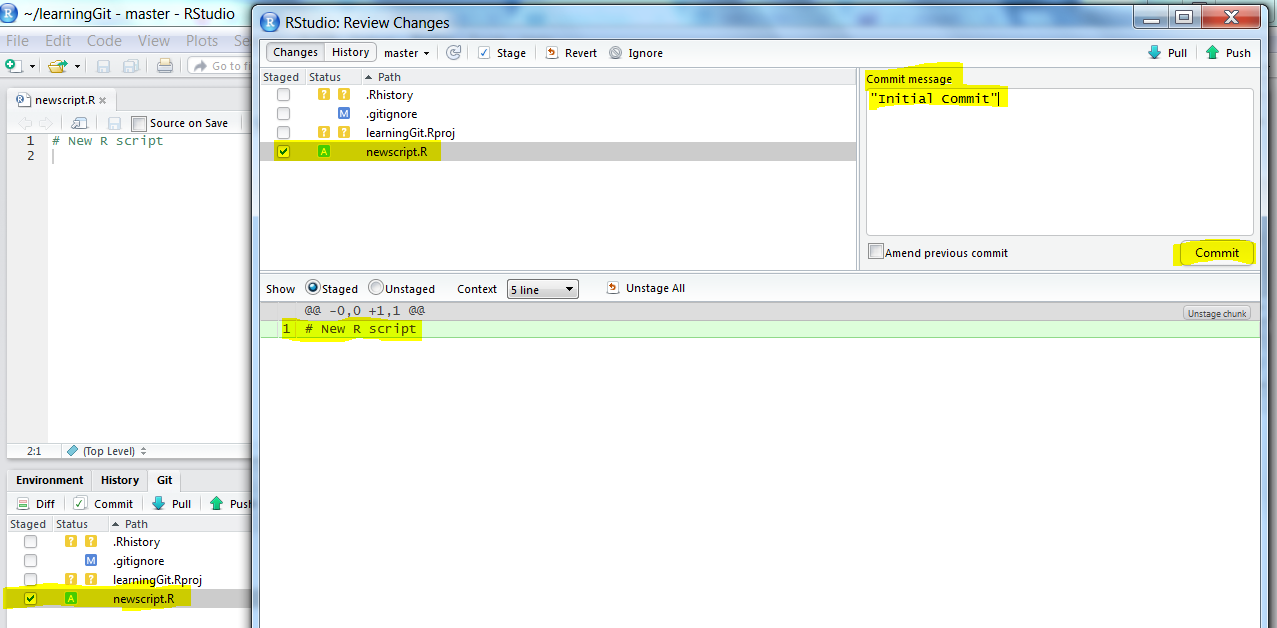
Staging and Commiting on RStudio
Finish by clicking Commit button and we should have staged and committed “newscript.R”. To upload to our GitHub account, we simply click Push while at “Git pane” and we would have a successful “push” made to our account: Confirm by opening your GitHub “learningGit” repo.
Push progress on RStudio
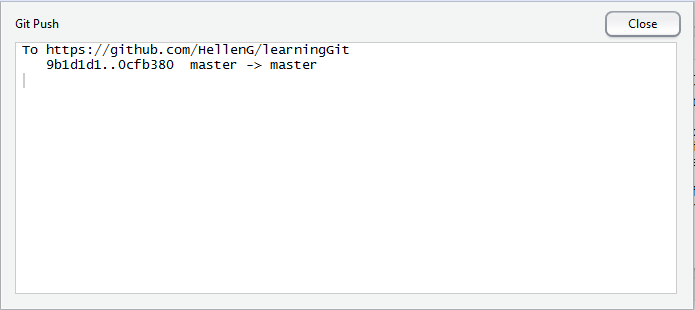
Notification of Pushed commits
I now leave you to attempt to make a new directory and version control it as well as look for a public repo to clone (consider “https://github.com/hadley/adv-r”).
References
- Pro GIT - chapter’s Reference Book on matters Git and GitHub: https://progit2.s3.amazonaws.com/en/2016-01-30-9e7cf/progit-en.1005.pdf) (main reference point)
- Version Control with Git by Michael Koby (of CodeCast.tv); *http://codecasts.tv/*. Considers it a video demonstrating Pro Git Book
- Basic Git Command Line Reference for Windows Users: *https://www.codeproject.com/Articles/457305/Basic-Git-Command-Line-Reference-for-Windows-Users*
- RStudio Projects: *https://support.rstudio.com/hc/en-us/articles/200526207*
- Version Control in RStudio: *https://support.rstudio.com/hc/en-us/articles/200532077-Version-Control-with-Git-and-SVN*